Linux下用Wget命令克隆获取整站/仿站
2020年3月29日星期日 | | 0 评论 |通过如下命令可以整个网站的源码下载到本地
wget -m -e robots=off https://www.fjbjdd.com
-m是克隆整个网站,-e robots=off是让wget忽视robots.txt
如果网站有中文路径,最好用以下命令
wget -r -p -np -k --restrict-file-names=nocontrol http://www.fjbjdd.com
Wget参数说明:
-r --recursive(递归) specify recursive download.(指定递归下载)
-k --convert-links(转换链接) make links in downloaded HTML point to local files.(将下载的HTML页面中的链接转换为相对链接即本地链接)
-p --page-requisites(页面必需元素) get all images, etc. needed to display HTML page.(下载所有的图片等页面显示所需的内容)
-np --no-parent(不追溯至父级) don't ascend to the parent directory.
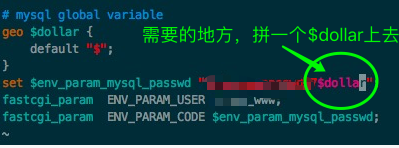
这里写代码片额外参数:
-nc 断点续传
-o 生成日志文件